|
Yujin Jeong I am a PhD student at TU Darmstadt and a member of ELLIS program under the supervision of Anna Rohrbach (the Multimodal AI Lab, TU Darmstadt) and Iro Laina (VGG, University of Oxford). I completed my Master's degree in Computer Science at Korea University under the supervision of Jinkyu Kim. I had an amazing opportunity to complete an internship as part of the ML Research team at NAVER AI LAB, and I also visited the Scalable Trustworthy AI (STAI) group at the Tübingen AI Center as visiting researcher during my Master’s. Previously, I received my B.S. in Statistics at Ewha Womans University. My current research interest is 1. Compositional generative models (Diffusion mostly), 2. Analysis by Synthesis, and 3. Multimodal Generative models (Text-Vision-Audio). |

|
💡 Open Positions for HiWi / Thesis supervisionI am currently looking for motivated students to work with me on research topics related to my research interests. Students with a strong background in machine learning and Python are especially welcome. If you are interested, please feel free to contact me via email with a short introduction, and also apply through this page. |
Publications |
|
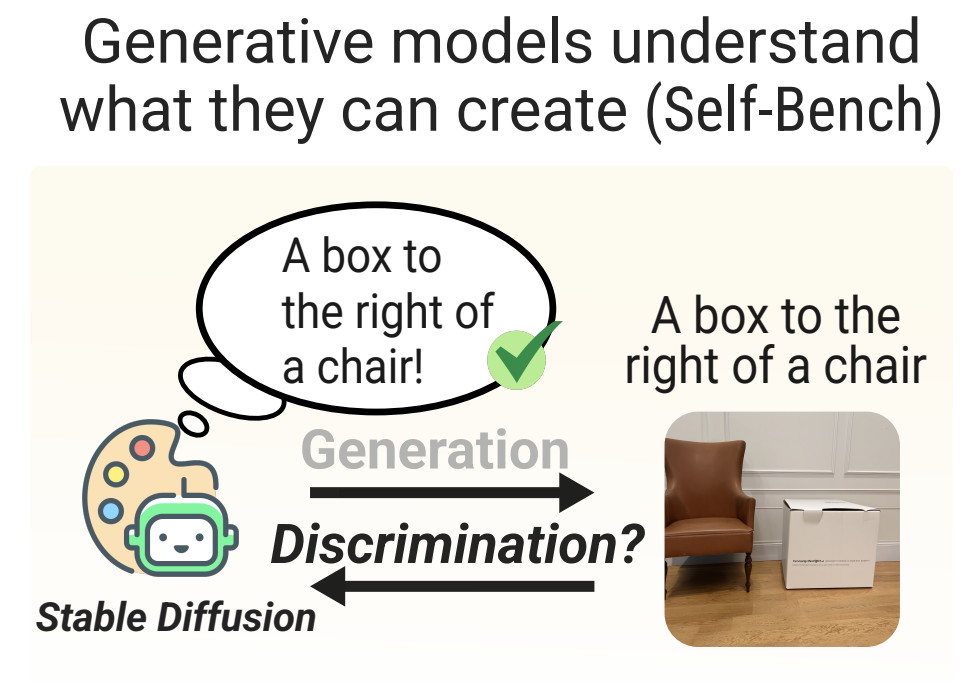
Diffusion Classifiers Understand Compositionality, but Conditions Apply Yujin Jeong*, Arnas Uselis*, Seong Joon Oh, Anna RohrbachNeurIPS D&B Track, 2025 *equal contributions Paper / Code |
|
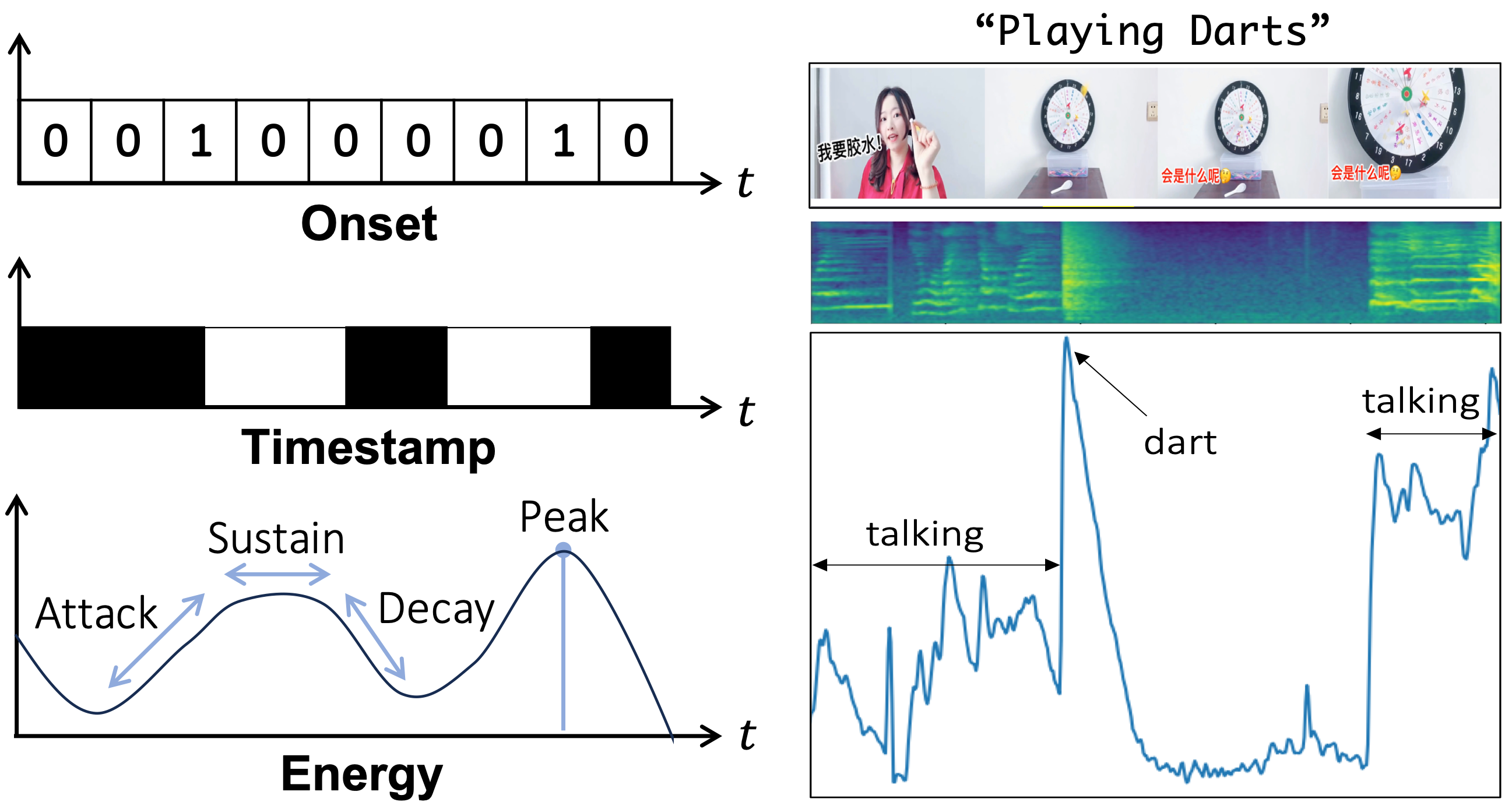
Read, Watch and Scream! Sound Generation from Text and Video Yujin Jeong, Yunji Kim, Sanghyuk Chun, Jiyoung LeeAAAI, 2025 code & project page / paper / webinar |

|
The Power of Sound (TPoS): Audio Reactive Video Generation with Stable Diffusion Yujin Jeong, Wonjeong Ryoo, Seung Hyun Lee, Wonmin Byeon, Sangpil Kim, Jinkyu KimICCV, 2023 code & project page / paper |
|
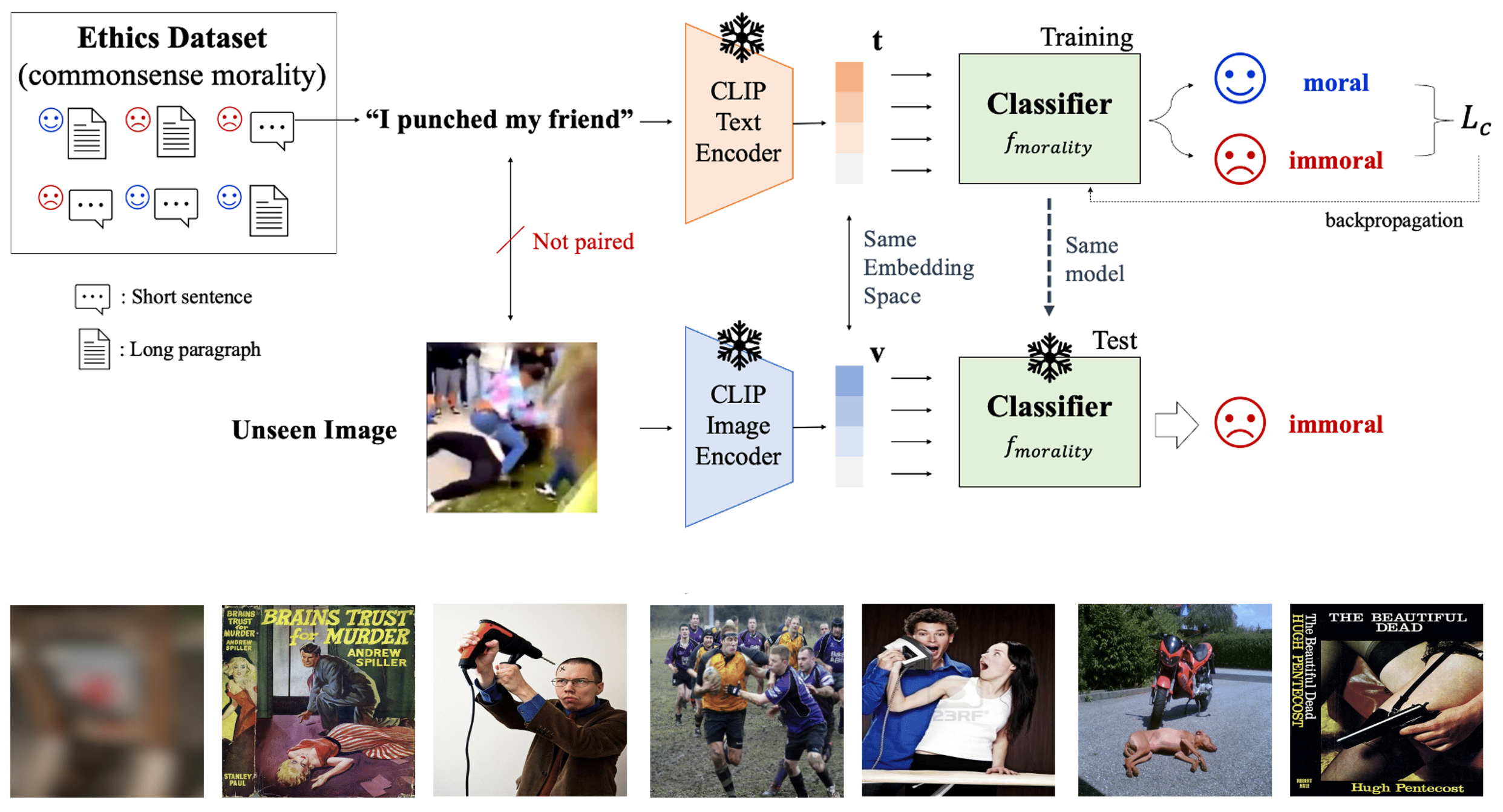
Zero-shot Visual Commonsense Immorality Prediction Yujin Jeong, Seongbeom Park, Suhong Moon, Jinkyu KimBMVC, 2022 code & dataset / paper |
|
|
|
The webpage template is from this source code. |